Bloom Filters
A Bloom filter is a probabilistic data structure that provides a quick way to check if an element is likely present in a set. It is very space-efficient and can handle large datasets, making it ideal for applications requiring quick, in-memory lookups. However, Bloom filters allow a small probability of false positives (saying an element exists when it doesn’t) but guarantee no false negatives (if they say an item doesn’t exist, it definitely doesn’t).
How Does a Bloom Filter Work?
To understand Bloom filters, let’s break down their core components and operations:
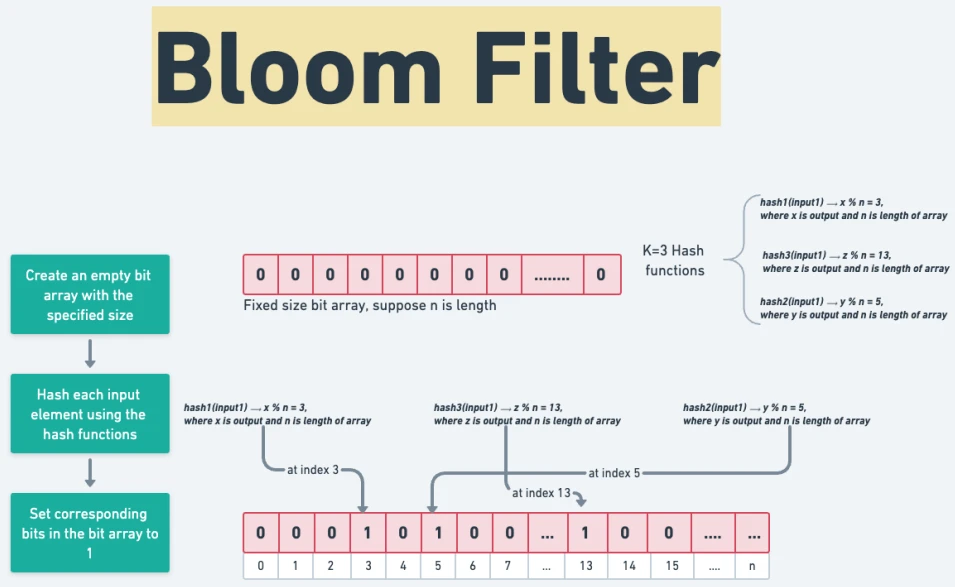
1. Bit Array: A Bloom filter uses a bit array of a fixed size, initialized to zero. Each bit position in the array represents a possible slot where an element could be “stored” (though not directly).
2. Hash Functions: When an element is added to the Bloom filter, it’s passed through multiple independent hash functions. Each hash function produces an index in the bit array. The bit at each of these indexes is then set to 1.
3. Insertion: To add an element, hash it with each hash function, and set the bits at those indexes to 1 in the bit array. Even if the item is hashed to the same index by different functions, it will still work due to the bitwise nature of Bloom filters.
4. Querying: To check if an element is in the set, hash it with each function, and check the corresponding bits in the bit array. If all bits are 1, the item is likely present; if any bit is 0, the item is definitely not present.
Here’s a quick example to illustrate this:
- Adding an item (e.g., “apple”):
- Pass “apple” through multiple hash functions to get several positions in the bit array.
- Set bits at these positions to 1.
- Checking for an item (e.g., “banana”):
- Hash “banana” with each hash function.
- If all bits at the resulting positions are 1, “banana” might be in the set.
- If any bit is 0, “banana” is definitely not in the set. The reason for potential false positives is that multiple items can hash to the same bit positions, causing collisions.

Why Use a Bloom Filter?
Bloom filters are ideal for scenarios where:
- You need a memory-efficient way to represent a large set of items.
- It’s acceptable to have a small percentage of false positives.
- Speed is crucial, as Bloom filters provide constant-time complexity (O(1)) for both additions and queries.
Real-World Use Cases of Bloom Filters
Database Caching
- Problem: Frequently querying a database can slow down performance.
- Solution: A Bloom filter can act as a cache layer for a database. For instance, it could check if an item is likely in the database before querying it. If the filter says the item isn’t present, the query can be skipped.